Abstract
Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often
complex and ambiguous, yet agents must execute deterministic actions to satisfy them.
To address this gap, we introduce CoVe (Constraint-Verification),
a post-training data synthesis framework designed for training interactive tool-use agents
while ensuring both data complexity and correctness.
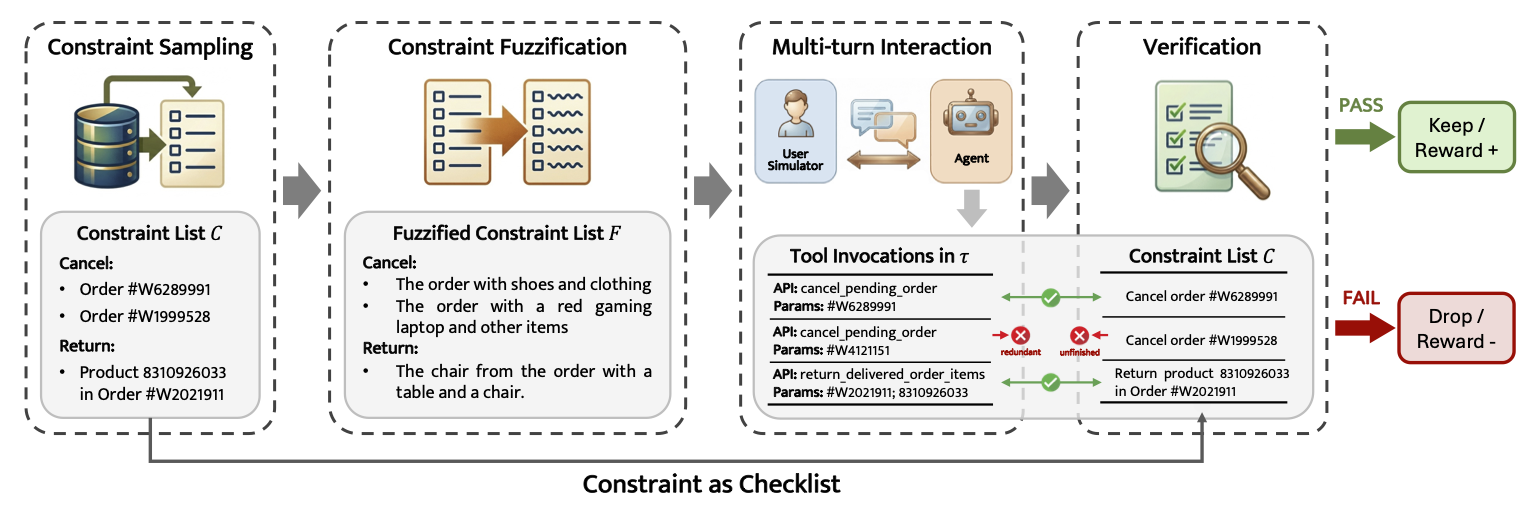
CoVe begins by defining explicit task constraints, which serve a dual role: they guide the
generation of complex trajectories and act as deterministic verifiers for assessing
trajectory quality. This enables the creation of high-quality training trajectories for
supervised fine-tuning (SFT) and the derivation of accurate reward signals for
reinforcement learning (RL).
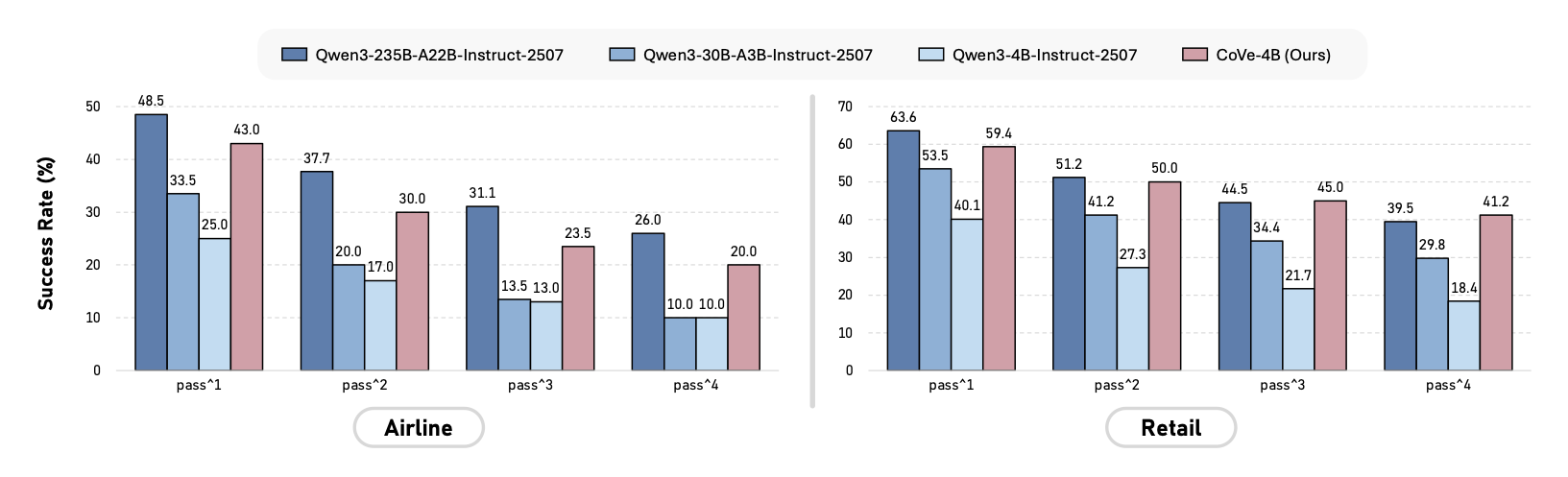
Our evaluation on the challenging τ2-bench benchmark demonstrates the effectiveness
of the framework. Notably, our compact CoVe-4B model achieves success rates of
43.0% and 59.4% in the Airline and Retail domains, respectively; its overall
performance significantly outperforms strong baselines of similar scale and remains competitive
with models up to 17× its size.
To support future research, we open-source our code, trained model, and the full set of
12K high-quality trajectories used for training.
51.2%
pass1 Average (CoVe-4B)
12K
High-quality trajectories (open-sourced)
17×
Competitive with models up to this size
+18.6%
Absolute improvement over base model
 CoVe: Training Interactive Tool-Use Agents
CoVe: Training Interactive Tool-Use Agents